Apply to become a certified provider
Apply to become a certified provider
About ISLRN
Every object in the world requires a kind of identification in order to be correctly recognised. Traditional printed material like books, for example, have generally used the International Standard Book Number (ISBN), the Library of Congress Control Number (LCCN), the Digital Object Identifier (DOI) and several other numeric identifiers as a unique identification scheme. Book identifiers allow us to easily identify books in a unique way. Other domains make use of several other identifier schemes. For instance, it is not rare to run into contact with an International/European Article Number (EAN), which is a universal barcoding system for everyday products. Each of these schemes seems to have been the output of some specific need or circumstance within a domain.
After having reviewed existing identification schemas, we conclude for the need to establish a specific identifier for LRs. Hence, we are introducing a new identifier scheme for Language Resources (LRs), namely, the International Standard Language Resource Number (ISLRN). It is meant to provide LRs with unique identifiers using a standardised nomenclature. This will ensure that LRs are correctly identified, and consequently, recognised with proper references for their usage in applications in R&D projects, products evaluation and benchmark as well as in documents and scientific papers. Moreover, it is a major step in the networked and shared world that Human Language Technologies (HLT) has become: unique resources must be identified as they are and meta-catalogues need a common identification format to manage data correctly. Therefore, LRs should carry identical identification schemes independently of their representations, whatever their types and wherever their physical locations (on hard drivers, Internet or Intranet) may be.
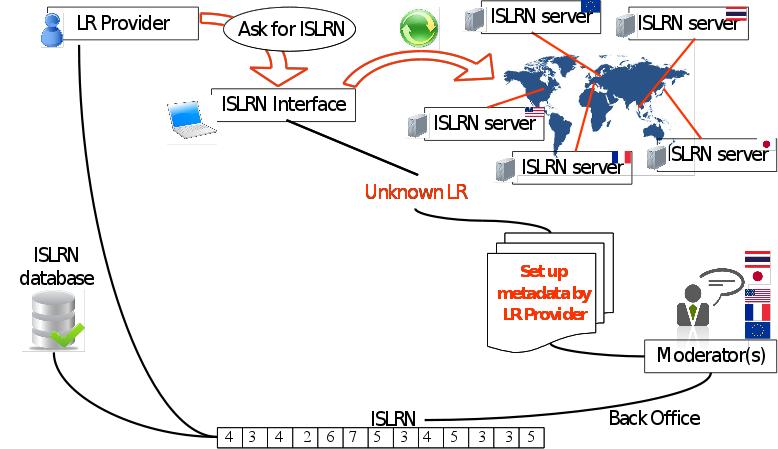
Proposal for the ISLRN management structure:

ISLRN attribution approach: